目录
正文
浅谈数据库索引的结构设计与优化
一. 了解数据库索引的必要性
对于稍微数据量大一点的表,如果不适用索引,那么性能效率都会很低;如果绕开了索引,直接进行分区分表,数据库集群读写分离来解决性能问题的话,那么未免也太小题大做了。
对于大多数中小型系统,索引能够帮你解决90%的性能问题,所以索引是解决关系型数据库非常有利的武器。
二. 表和索引结构
1.索引页和表页
表和索引都是存在页中。页的大小一般是4KB.页的大小仅仅决定了一个页能存储多少个索引行,表行。
2.索引行
索引行是很有用的一个概念对于访问路径的时候。索引行的概念可以通过下图来了解:
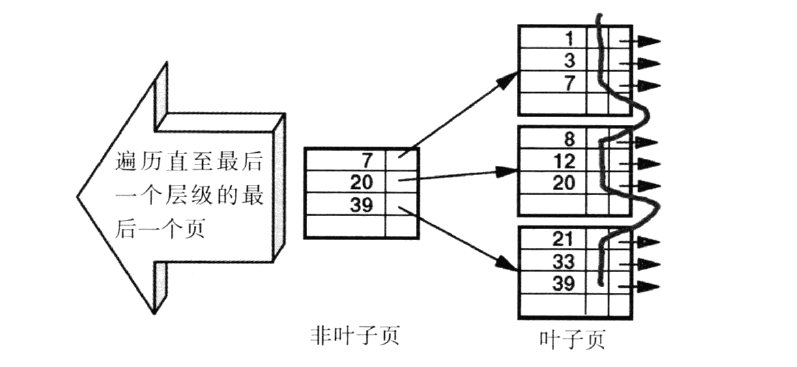
每一个页上包含了很多索引行,每个索引行里存储着索引条目和指向下一层的页,这种数据结构为B-tree结构。
3.缓冲池和磁盘I/O
我们可以使用内存的缓冲池来减小到磁盘的访问。这一策略对sql性能表现至关重要。下图展示了磁盘读取到缓冲区的巨大成本:

当我们需要某一页的一行数据时,和需要这一页的数据时,所花费的时间是相等的。可以通过执行:show global status like 'innodb%read%';来判断缓存命中的情况,具体的参数可以自行在网上查找:

可以算出来缓存命中率为=260850/(64+260850+1927)=99.24%,是很高的命中率了。
4.硬件特性
硬盘磁盘的图可以用下图简单表示:

我们的数据库表里的数据就保存在磁盘上,如果要读取数据,就要砖头磁盘,用磁头和磁盘的磁力来改变状态,来读取数据,所以,我们应该尽量少的转动磁盘,来优化数据库性能。
那么这个就有一个组合谓词,组合谓词是索引设计的主要入手点。
2.过滤因子
过滤因子是描述谓词的选择性,它主要依赖于列值的分布情况。它是一个计算值,公式为:

用来计算谓词结果集的返回大小估算。
3.物化结果集
是执行数据库访问来构建结果集。最好的情况下,是从数据库缓冲池返回一条记录,最坏的情况就是访问大量的磁盘读取数据。
物化结果集有2种方式:
1.一次FETCH物化返回一条数据
2.提前物化

{kind=link}
{kind=link}
{kind=link}